Showing posts with label SQL. Show all posts
Showing posts with label SQL. Show all posts
Sunday, 24 January 2016
SQL Database Performance Tuning for Developers
Hi,
Recently I came across a great post about SQL Performance Tuning Tips n Tricks, which outlines a good deal of information across all the common features we leverage off in our day to day business.
SQL Database Performance Tuning for Developers
This post has helped me also to gain insights into some of the areas of temp DB sql as well.
Hope it helps.
Friday, 4 May 2012
Excel VBA Data Warehouse Generator Tool
Recently I was observing our database development team, and I observed that much of my colleagues were struggling with lots of boiler plate code. In the process of generating Dimension and Fact tables (in snow flaked schema), I thought it would be nice to create an easy to use tool to generate database schema with the following rules in place:
1. Each dimension table would have a primary key, combined with identity auto generation.
2. A dimension table may have referential constraint upon another dimension table
3. A fact table will have multiple referential constraints from multiple dimension tables but not from any other factual table.
4. A fact table will not have a primary key nor an identity column.
This tool is primarily an assisting tool for repetitive process occurred in the data warehouse table structure generation, though for any other design requirements developer intervention is very much required to meet the special conditions.

To use the tool, there is a main page where all the relevant information needs to be set like connection string, script folder path and updated database on which the operation needs to be performed once the list is refreshed.
Control Page:

Dimension Page:

Fact Page:
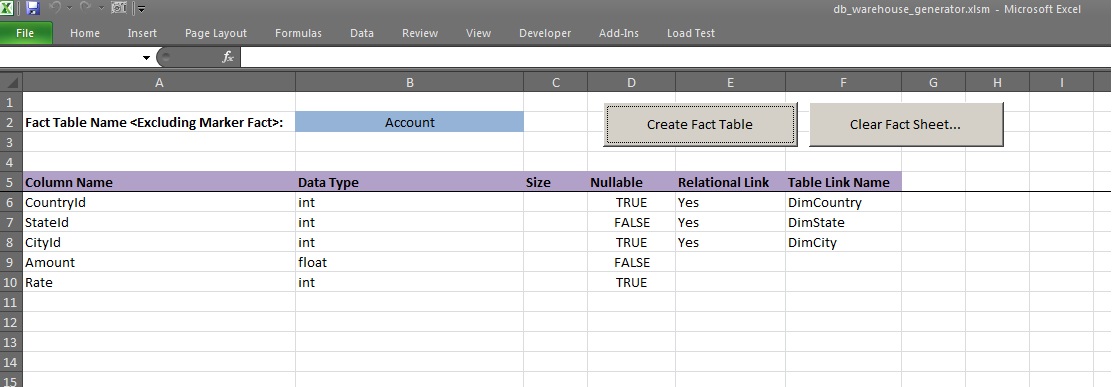
Then there is a SQL Server Management Studio style dimension and fact table generation worksheets where user can set the desired columns required according to the business needs along with integrated drop down list on the Table Link column where the refrence dimension tables can be selected(The table name for dimension and fact wil be appended by keywords "Dim" and "Fact" respectivly. And also for the dimension tables the key columns as they will be auto generated via VBA and appended terms like "Id").

Download solution
1. Each dimension table would have a primary key, combined with identity auto generation.
2. A dimension table may have referential constraint upon another dimension table
3. A fact table will have multiple referential constraints from multiple dimension tables but not from any other factual table.
4. A fact table will not have a primary key nor an identity column.
This tool is primarily an assisting tool for repetitive process occurred in the data warehouse table structure generation, though for any other design requirements developer intervention is very much required to meet the special conditions.
To use the tool, there is a main page where all the relevant information needs to be set like connection string, script folder path and updated database on which the operation needs to be performed once the list is refreshed.
Control Page:
Dimension Page:
Fact Page:
Then there is a SQL Server Management Studio style dimension and fact table generation worksheets where user can set the desired columns required according to the business needs along with integrated drop down list on the Table Link column where the refrence dimension tables can be selected(The table name for dimension and fact wil be appended by keywords "Dim" and "Fact" respectivly. And also for the dimension tables the key columns as they will be auto generated via VBA and appended terms like "Id").
Download solution
Thursday, 22 December 2011
Recursion vs. Loops in VBA and SQL
Recursion, when I was first taught about it in our class rooms our professor mentioned, this is one topic which every student ask to repeat once again.
Though after a while in the business I am learning actually it’s not that bad too. But it’s just a concept which has to be used wisely. In the past the context I have used recursion is for file/directory searches and listing. But I was also taught to us in the context of factorial and mathematical concepts which could be achieved via loops.
Thus I am embarking in this post to figure out which is a better one to choose:
With recursion, though our mathematical models can be represented well in comparison to loops programmatically. The concept of recursion has some underlying concerns which also need to be taken into account while designing the programs.
The following concerns are sourced from MSDN (for further details please refer to the detailed MSDN documentation):
1. Limiting condition: This is the most important part of recursion and upon which many times my programs have crashed up. Design the recursion ending condition well for all scenarios of the input, if not you might end up into stack overflow error.
2. Memory Usage/Performance: This is one of the most important considerations to take into account while writing code for recursion. As the function/procedure calls upon itself each time the copy of local variable for each instance of execution is created on stack and the overhead of argument passing has to be taken.
3. Debug: Painful to debug in recursive codes.
So rather stick with Looping?? Well it’s an answer you as developer have to decide which route to take; personally I have used recursion for scenarios of file/directory listing arenas and mostly stick to the simple forms of looping for any other tasks of computations. But your comments are valuable for me in this space .. !!!
Below are the codes to illustrate the use of recursion in VBA and in SQL (too but only limited to 32 levels)
VBA:
Note: For SQL Stored Procedures CAN call Stored Procedures & Functions(Both), but Functions CAN call Functions (Only).
Refrences:
Link1 (MSDN Recursion): http://msdn.microsoft.com/en-us/library/81tad23s%28v=vs.80%29.aspx
Link2: http://stackoverflow.com/questions/660337/recursion-vs-loops
Though after a while in the business I am learning actually it’s not that bad too. But it’s just a concept which has to be used wisely. In the past the context I have used recursion is for file/directory searches and listing. But I was also taught to us in the context of factorial and mathematical concepts which could be achieved via loops.
Thus I am embarking in this post to figure out which is a better one to choose:
With recursion, though our mathematical models can be represented well in comparison to loops programmatically. The concept of recursion has some underlying concerns which also need to be taken into account while designing the programs.
The following concerns are sourced from MSDN (for further details please refer to the detailed MSDN documentation):
1. Limiting condition: This is the most important part of recursion and upon which many times my programs have crashed up. Design the recursion ending condition well for all scenarios of the input, if not you might end up into stack overflow error.
2. Memory Usage/Performance: This is one of the most important considerations to take into account while writing code for recursion. As the function/procedure calls upon itself each time the copy of local variable for each instance of execution is created on stack and the overhead of argument passing has to be taken.
3. Debug: Painful to debug in recursive codes.
So rather stick with Looping?? Well it’s an answer you as developer have to decide which route to take; personally I have used recursion for scenarios of file/directory listing arenas and mostly stick to the simple forms of looping for any other tasks of computations. But your comments are valuable for me in this space .. !!!
Below are the codes to illustrate the use of recursion in VBA and in SQL (too but only limited to 32 levels)
VBA:
Option Explicit
Public Function recursive_fact(n As Integer) As Integer
If n < 1 Then
recursive_fact = 1
Exit Function
End If
recursive_fact = n * recursive_fact(n - 1)
End Function
Public Function looping_fact(n As Integer) As Integer
Dim jCount As Integer
looping_fact = 1
For jCount = n To 1 Step -1
looping_fact = looping_fact * jCount
Next jCount
End Function
Sub test_functions()
Dim iCount As Integer
Dim jCount As Integer
iCount = 5
jCount = 5
iCount = recursive_fact(iCount)
jCount = looping_fact(jCount)
Debug.Print "Factorial of iCount: " & iCount
Debug.Print "Factorial of jCount: " & jCount
End Sub
'--Output--
'Factorial of iCount: 120
'Factorial of jCount: 120
SQL:--Create a sample table
CREATE TABLE employee(
id INTEGER NOT NULL PRIMARY KEY,
first_name VARCHAR(10),
last_name VARCHAR(10),
salary DECIMAL(10,2),
start_Date DATETIME,
region VARCHAR(10),
city VARCHAR(20),
managerid INTEGER
);
--Insert some records into it
INSERT INTO employee VALUES (1, 'Jason' , 'Martin', 5890,'2005-03-22','North','Vancouver',3);
GO
INSERT INTO employee VALUES (2, 'Alison', 'Mathews',4789,'2003-07-21','South','Utown',4);
GO
INSERT INTO employee VALUES (3, 'James' , 'Smith', 6678,'2001-12-01','North','Paris',5);
GO
INSERT INTO employee VALUES (4, 'Celia' , 'Rice', 5567,'2006-03-03','South','London',6);
GO
INSERT INTO employee VALUES (5, 'Robert', 'Black', 4467,'2004-07-02','East','Newton',7);
GO
INSERT INTO employee VALUES (6, 'Linda' , 'Green' , 6456,'2002-05-19','East','Calgary',8);
GO
INSERT INTO employee VALUES (7, 'David' , 'Larry', 5345,'2008-03-18','West','New York',9);
GO
INSERT INTO employee VALUES (8, 'James' , 'Cat', 4234,'2007-07-17','West','Regina',9);
GO
INSERT INTO employee VALUES (9, 'Joan' , 'Act', 6123,'2001-04-16','North','Toronto',10);
GO
--Verify the data
SELECT * FROM employee;
GO
--Create the procedure
CREATE PROC usp_FindBoss(
@EmployeeID int
)
AS
DECLARE @ReportsTo int
SELECT
@ReportsTo = managerid
FROM
Employee
WHERE
Id = @EmployeeID
IF @ReportsTo IS NOT NULL AND @@NESTLEVEL <= 32
BEGIN
SELECT
@EmployeeID AS Employee,
@ReportsTo AS Manager
EXEC usp_FindBoss
@ReportsTo
END
GO
--Execute the procedure
SELECT * FROM employee
EXEC usp_FindBoss 2
Note: For SQL Stored Procedures CAN call Stored Procedures & Functions(Both), but Functions CAN call Functions (Only).
Refrences:
Link1 (MSDN Recursion): http://msdn.microsoft.com/en-us/library/81tad23s%28v=vs.80%29.aspx
Link2: http://stackoverflow.com/questions/660337/recursion-vs-loops
Monday, 17 October 2011
MySQL: User Activity Tracking (Bandwidth)
Recently I was presented a question whether it would be possible on MySQL to track the user activity in terms of queries and the amount of data downloaded by the individual user from the database.

Thus in the quest I came across a brilliant tool named “MySQL Proxy”. This tool provides a very strong functionality for MySQL database, which includes multiple MySQL server load balancing, query injection, and much more. This tool provided a very robust solution for the request with the usage of Lua scripting. Rather me extending more benefits about the tool in the post, I provide all the references below for the readers to explore more benefits of the tool themselves and here I would like to present my solution to record user activity in MySQL using MySQL Proxy with the following Lua script.
Note: This script also provides a section where user can be prohibited to download more data than the specified limit.
Download:
Download solution
Thus in the quest I came across a brilliant tool named “MySQL Proxy”. This tool provides a very strong functionality for MySQL database, which includes multiple MySQL server load balancing, query injection, and much more. This tool provided a very robust solution for the request with the usage of Lua scripting. Rather me extending more benefits about the tool in the post, I provide all the references below for the readers to explore more benefits of the tool themselves and here I would like to present my solution to record user activity in MySQL using MySQL Proxy with the following Lua script.
Note: This script also provides a section where user can be prohibited to download more data than the specified limit.
-- measures bandwidth by user
proxy.global.bandwidth = proxy.global.bandwidth or {}
local session_user
local sqlQuery
local before_bytes_sent = 0
local after_bytes_sent = 0
local before_bytes_recevied = 0
local after_bytes_recevied = 0
function read_auth()
session_user = proxy.connection.client.username
proxy.global.bandwidth[session_user] =
proxy.global.bandwidth[session_user] or 0
end
function read_query (packet )
-- just to show how we can block a user query
-- when the quota has been exceeded
if proxy.global.bandwidth[session_user] > 10000
and session_user ~= 'root'
then
return error_result('you have exceeded your query quota')
end
sqlQuery = string.sub(packet, 2)
proxy.global.bandwidth[session_user ] =
proxy.global.bandwidth[session_user] + packet:len()
proxy.queries:append(1, string.char(proxy.COM_QUERY) .. "SHOW SESSION STATUS LIKE '%Bytes%'", {resultset_is_needed = true} )
proxy.queries:append(2, packet,{resultset_is_needed = true})
proxy.queries:append(3, string.char(proxy.COM_QUERY) .. "SHOW SESSION STATUS LIKE '%Bytes%'", {resultset_is_needed = true} )
return proxy.PROXY_SEND_QUERY
end
function read_query_result(inj)
if (inj.id == 4) then
return proxy.PROXY_IGNORE_RESULT
end
if (inj.id == 1) or (inj.id == 3) then
for row in inj.resultset.rows do
if (row[1] == "Bytes_sent") and (inj.id == 1) then
before_bytes_sent = row[2]
end
if (row[1] == "Bytes_sent") and (inj.id == 3) then
after_bytes_sent = row[2]
end
if (row[1] == "Bytes_received") and (inj.id == 1) then
before_bytes_recevied = row[2]
end
if (row[1] == "Bytes_received") and (inj.id == 3) then
after_bytes_recevied = row[2]
end
end
if (inj.id == 3) then
print("Bytes sent before: " .. before_bytes_sent)
print("Bytes sent after: " .. after_bytes_sent)
print("Bytes received before: " .. before_bytes_recevied)
print("Bytes received after: " .. after_bytes_recevied)
print("Net Bytes sent: " .. (after_bytes_sent - before_bytes_sent))
print("Net Bytes received: " .. (after_bytes_recevied - before_bytes_recevied))
print("Username: " .. session_user)
print("Query: " .. sqlQuery)
print("DateTime: " .. os.date("%Y-%m-%d %H:%M:%S"))
insert_log_query(session_user, os.date("%Y-%m-%d %H:%M:%S"), sqlQuery, (after_bytes_sent - before_bytes_sent), (after_bytes_recevied - before_bytes_recevied))
end
return proxy.PROXY_IGNORE_RESULT
end
end
function insert_log_query(username, date_time, query , net_bytes_sent, net_bytes_recived)
print(username, date_time, query , net_bytes_sent, net_bytes_recived)
proxy.queries:append(4, string.char(proxy.COM_QUERY) .. "INSERT INTO `employees`.`user_log` (`username`, `date_time`, `query`, `bytes_sent`, `bytes_recived`) VALUES ('" ..
username .. "','" .. date_time .. "',\"" .. query .. "\"," .. net_bytes_sent .. "," .. net_bytes_recived .. ");", {resultset_is_needed = true})
return proxy.PROXY_SEND_QUERY
end
This script uses the "SHOW SESSION STATUS" results for the recording of bytes sent and recevied. This also illustrates the power of MySQL Proxy which enables use to inject addtional queries to the database
and process their results to our needs without any affects visible to the end user.Download:
Download solution
References:
Link2: http://forge.mysql.com/wiki/MySQL_Proxy_Cookbook
Sunday, 16 October 2011
MySQL Large Table: Split OR Partitioning???
For couple of past months this question has puzzled me at my work. And seeking answers over the internet, I wasn’t able to find a specific answer to the question. So in this post I would only like to highlight my experiences so far with my decision, with no bias to any particular method.
Table Split Vs Partitioning, this decision should be primarily based on the context of usage pattern of the database and type of queries being executed on the database on regular basis/users of the database.
When to split table into smaller tables:
• If the queried table is being scanned on non regular columns (i.e. the queries “Where” clause always changes to different columns within the table)
• If the queries are analytical in nature and direct users of the database are business users.
• If the partition mechanism has to span more than 1024 partition (MySQL limitation)
The disadvantage of splitting the table into multiple tables, highlight problems relevant to querying the database upon multiple tables (with usage of dynamic SQL within stored procedures), complex logic, creation of large number of tables and further more. But these problems outweigh the benefits achieved for analytical purposes once the system is set, keeping it in simple terms with each query upon spliced tables has fewer rows to scan physically and hence forth the results are faster with union all’ed result presented and consistent across any column scan involved in the query.
When to partition a table:
• If the queries are mostly regular in nature or database acts as a backend to the business system (i.e. the majority of queries “Where” clause is using the same column for scan within the table).
• The use of database if limited to storing of records and retrieval of records on standard parameters (i.e. non analytical purposes).
• Where database is being utilized by ORM mechanisms like ADO.NET/Hibernate.
• Foreign keys are not supported on partitioned table.
The disadvantage of partitioned table within an analytical environment is some times more detrimental in terms of performance than the advantages it results into. This is due to the fact when the column scans is performed on the partitioned table upon which the table is not partitioned is employs mysql more effort to scan the each partition of the table for the results and query execution is slower than the table split. But also to mention in spite of the partitioning mechanism used one should also take care of the mechanism of “Partition Pruning” related to the where clause in the select queries illustrating the mysql which partitions to scan for the result.
Performance Results:
In the experiment table contains 28,44,042 rows with "from_date" being indexed:
Note: all the tables in the example are partitioned on the “from_date” column in the table.
Comparison Table:
Though I do not wish to end this trail in here and I would like to know reader opinions and thoughts about this topic and shed more light whether the table split is better than partitioning or vice versa.
Look forward to your comments …
References:
Link1: http://dev.mysql.com/doc/refman/5.1/en/partitioning.html
Table Split Vs Partitioning, this decision should be primarily based on the context of usage pattern of the database and type of queries being executed on the database on regular basis/users of the database.
When to split table into smaller tables:
• If the queried table is being scanned on non regular columns (i.e. the queries “Where” clause always changes to different columns within the table)
• If the queries are analytical in nature and direct users of the database are business users.
• If the partition mechanism has to span more than 1024 partition (MySQL limitation)
The disadvantage of splitting the table into multiple tables, highlight problems relevant to querying the database upon multiple tables (with usage of dynamic SQL within stored procedures), complex logic, creation of large number of tables and further more. But these problems outweigh the benefits achieved for analytical purposes once the system is set, keeping it in simple terms with each query upon spliced tables has fewer rows to scan physically and hence forth the results are faster with union all’ed result presented and consistent across any column scan involved in the query.
When to partition a table:
• If the queries are mostly regular in nature or database acts as a backend to the business system (i.e. the majority of queries “Where” clause is using the same column for scan within the table).
• The use of database if limited to storing of records and retrieval of records on standard parameters (i.e. non analytical purposes).
• Where database is being utilized by ORM mechanisms like ADO.NET/Hibernate.
• Foreign keys are not supported on partitioned table.
The disadvantage of partitioned table within an analytical environment is some times more detrimental in terms of performance than the advantages it results into. This is due to the fact when the column scans is performed on the partitioned table upon which the table is not partitioned is employs mysql more effort to scan the each partition of the table for the results and query execution is slower than the table split. But also to mention in spite of the partitioning mechanism used one should also take care of the mechanism of “Partition Pruning” related to the where clause in the select queries illustrating the mysql which partitions to scan for the result.
Performance Results:
In the experiment table contains 28,44,042 rows with "from_date" being indexed:
Note: all the tables in the example are partitioned on the “from_date” column in the table.
#**Simple Table **
CREATE TABLE `salaries` (
`emp_no` INT(11) NOT NULL,
`salary` INT(11) NOT NULL,
`from_date` DATE NOT NULL,
`to_date` DATE NOT NULL,
PRIMARY KEY (`emp_no`, `from_date`),
INDEX `emp_no` (`emp_no`)
)
COLLATE='latin1_swedish_ci'
ENGINE=InnoDB
ROW_FORMAT=DEFAULT
#**Partition by month**
CREATE TABLE `salaries_copy` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`),
KEY `emp_no` (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 ROW_FORMAT=COMPACT
/*!50100 PARTITION BY HASH (Month(from_date))
PARTITIONS 12 */
#**Partition by Range**
CREATE TABLE `salaries_copy_1` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`),
KEY `emp_no` (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 ROW_FORMAT=COMPACT
/*!50100 PARTITION BY RANGE (to_days(from_date))
(PARTITION p0 VALUES LESS THAN (to_days('1985-01-01')) ENGINE = InnoDB,
PARTITION p1 VALUES LESS THAN (to_days(‘1986-01-01’)) ENGINE = InnoDB,
PARTITION p2 VALUES LESS THAN (to_days(‘1987-01-01’)) ENGINE = InnoDB,
PARTITION p3 VALUES LESS THAN (to_days('1988-01-01')) ENGINE = InnoDB,
PARTITION p4 VALUES LESS THAN (to_days('1989-01-01')) ENGINE = InnoDB,
PARTITION p5 VALUES LESS THAN (to_days('1990-01-01')) ENGINE = InnoDB,
PARTITION p6 VALUES LESS THAN (to_days('1991-01-01')) ENGINE = InnoDB,
PARTITION p7 VALUES LESS THAN (to_days('1992-01-01')) ENGINE = InnoDB,
PARTITION p8 VALUES LESS THAN (to_days('1993-01-01')) ENGINE = InnoDB,
PARTITION p9 VALUES LESS THAN (to_days('1994-01-01')) ENGINE = InnoDB,
PARTITION p10 VALUES LESS THAN (to_days('1995-01-01')) ENGINE = InnoDB,
PARTITION p11 VALUES LESS THAN (to_days('1996-01-01')) ENGINE = InnoDB,
PARTITION p12 VALUES LESS THAN (to_days('1997-01-01')) ENGINE = InnoDB,
PARTITION p13 VALUES LESS THAN (to_days('1998-01-01')) ENGINE = InnoDB,
PARTITION p14 VALUES LESS THAN (to_days('1999-01-01')) ENGINE = InnoDB,
PARTITION p15 VALUES LESS THAN (to_days('2000-01-01')) ENGINE = InnoDB,
PARTITION p16 VALUES LESS THAN (to_days('2001-01-01')) ENGINE = InnoDB,
PARTITION p17 VALUES LESS THAN (to_days('2002-01-01')) ENGINE = InnoDB,
PARTITION p18 VALUES LESS THAN (to_days('2003-01-01')) ENGINE = InnoDB,
PARTITION p19 VALUES LESS THAN (to_days('2004-01-01')) ENGINE = InnoDB,
PARTITION p20 VALUES LESS THAN (to_days('2005-01-01')) ENGINE = InnoDB,
PARTITION pmax VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */
#********* Test 1: Queries scanning the partitioned column: from_date ***********
Select SQL_NO_CACHE * From salaries tbl
where tbl.from_date >= '2000-03-15' and tbl.from_date < '2000-09-25';
#Duration for 1 query: 0.016 sec. (+ 2.137 sec. network)
Select SQL_NO_CACHE * From salaries_copy tbl
where tbl.from_date >= '2000-03-15' and tbl.from_date < '2000-09-25';
#Duration for 1 query: 2.106 sec. (+ 5.288 sec. network)
Select SQL_NO_CACHE * From salaries_copy_1 tbl
where tbl.from_date >= '2000-03-15' and tbl.from_date < '2000-09-25';
#Duration for 1 query: 0.063 sec. (+ 1.185 sec. network)
Select SQL_NO_CACHE * From salaries_1985
where salaries_1985.from_date >= '2000-03-15' and salaries_1985.from_date < '2000-09-25'
UNION ALL
Select * From salaries_1986
where salaries_1986.from_date >= '2000-03-15' and salaries_1986.from_date < '2000-09-25'
UNION ALL …
…
Select * From salaries_2005
where salaries_2005.from_date >= '2000-03-15' and salaries_2005.from_date < '2000-09-25';
#Duration for 1 queries: 1.638 sec. (+ 0.484 sec. network)
#********* Test 2: Queries scanning the non partitioned column: to_date ***********
Select SQL_NO_CACHE * From salaries tbl
where tbl.to_date >= '2000-03-15' and tbl.to_date < '2000-09-25';
#Duration for 1 query: 0.109 sec. (+ 2.762 sec. network)
Select SQL_NO_CACHE * From salaries_copy tbl
where tbl.to_date >= '2000-03-15' and tbl.to_date < '2000-09-25';
#Duration for 1 query: 1.201 sec. (+ 6.521 sec. network)
Select SQL_NO_CACHE * From salaries_copy_1 tbl
where tbl.to_date >= '2000-03-15' and tbl.to_date < '2000-09-25';
#Duration for 1 query: 7.472 sec. (+ 3.058 sec. network)
Select SQL_NO_CACHE * From salaries_1985
where salaries_1985.to_date >= '2000-03-15' and salaries_1985.to_date < '2000-09-25'
UNION ALL
Select * From salaries_1986
where salaries_1986.to_date >= '2000-03-15' and salaries_1986.to_date < '2000-09-25'
UNION ALL …
…
Select * From salaries_2005
where salaries_2005.to_date >= '2000-03-15' and salaries_2005.to_date < '2000-09-25';
#Duration for 1 query: 1.670 sec. (+ 0.483 sec. network)
Comparison Table:
| Query on “from_date” | Query on “to_date” | Description |
|---|---|---|
| Indexed column | Non-Indexed column | - |
| 0.016 sec. (+ 2.137 sec. network) | 0.109 sec. (+ 2.762 sec. network) | Simple table |
| 2.106 sec. (+ 5.288 sec. network) | 1.201 sec. (+ 6.521 sec. network) | Partition by HASH (Month(from_date)) |
| 0.063 sec. (+ 1.185 sec. network) | 7.472 sec. (+ 3.058 sec. network) | Partition by RANGE (to_days(from_date)) |
| 1.638 sec. (+ 0.484 sec. network) | 1.670 sec. (+ 0.483 sec. network) | Table Split by year(from_date) |
Though I do not wish to end this trail in here and I would like to know reader opinions and thoughts about this topic and shed more light whether the table split is better than partitioning or vice versa.
Look forward to your comments …
References:
Link1: http://dev.mysql.com/doc/refman/5.1/en/partitioning.html
Tuesday, 14 September 2010
Excel Power Tools: Turbo Charge Your Processing Power
Recently i have completed my first phase of an excel addin tool for the most general day to day purpose utility.
The commonly used functionality desired by analyst and business solutions is featured in this addin. This addin is mainly focused on improving the user efficiency, power and creativty.
Some of the key highlights of this tool are
1. Google Charts
2.Google Translation (via UDF)
3.Named Range Functionality and navigation
4. SQL/Access Intellisense
5. Generic quick sort implementation as UDF for tables maintining relative column.
6. Range/Chart export as image
7. Workbook Name Navigator
8. Calender
9. Automated Formula Replacer
10. Visual Audit Tool for Formula Extension
11. Range Concatenation
and tons of more features to get you excited and highly simplified and organised design for the users to load on the future functional implemntations...
Link to Addin:

Download solution
I look forward to your comment and future suggestions for the added functionalities.
Addin Screenshots:
The commonly used functionality desired by analyst and business solutions is featured in this addin. This addin is mainly focused on improving the user efficiency, power and creativty.
Some of the key highlights of this tool are
1. Google Charts
2.Google Translation (via UDF)
3.Named Range Functionality and navigation
4. SQL/Access Intellisense
5. Generic quick sort implementation as UDF for tables maintining relative column.
6. Range/Chart export as image
7. Workbook Name Navigator
8. Calender
9. Automated Formula Replacer
10. Visual Audit Tool for Formula Extension
11. Range Concatenation
and tons of more features to get you excited and highly simplified and organised design for the users to load on the future functional implemntations...
Link to Addin:
Download solution
I look forward to your comment and future suggestions for the added functionalities.
Addin Screenshots:
Subscribe to:
Posts (Atom)